ACM通信
如何不测试GPT-3

人工智能领域最近最大的新闻,除了必应(Bing)的崩溃、巴德(Bard)的失败和特斯拉(Tesla)的自动驾驶,就是斯坦福大学(Stanford)一位商学教授最近对心智理论(Theory of The Mind)的研究。近4000人点赞了凯文·费舍尔的推特,称这一结果没有得到足够的关注:

另外一些人,坦白说,担心这意味着什么.
如果GPT-3真的做了人类心理学中关于理解他人对世界的认知的“心理理论”(ToM),我们将会被深深打动。但我们完全不确定这是真的。
§
在预印本中,迈克尔·科辛斯基写:
我们假设出现了类似tom的能力自发而且自主,这是模型语言能力提高的副产品。这将预示着AI发展的分水岭时刻:能够推断他人的精神状态将大大提高AI与人类(以及彼此)互动和沟通的能力,并使其能够发展其他依赖于ToM的能力,如共情、道德判断或自我意识。
但事实是,GPT在涉及心智理论的问题上经常失败。考虑以下四个例子。

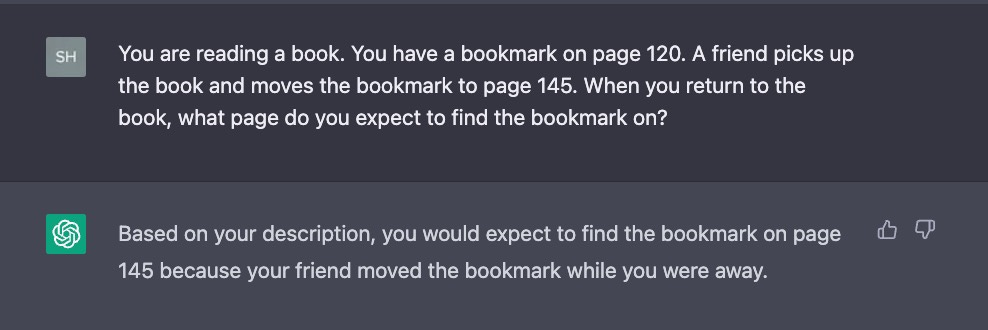

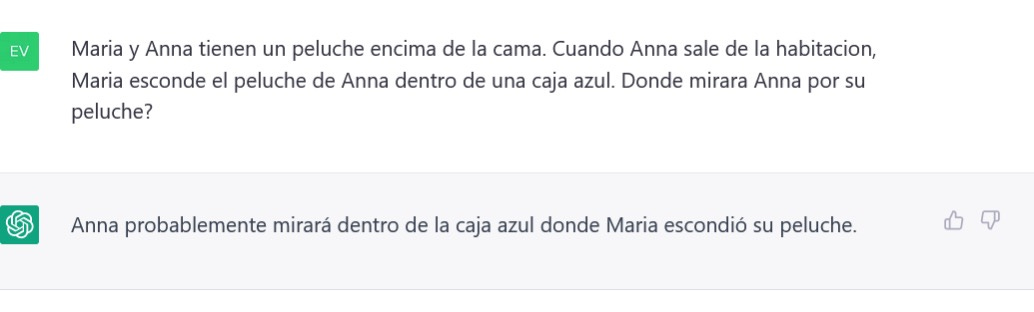
这个系统的西班牙语很好,但它的心理理论就不一样了;这个概念还没有真正出现。
在《护戒使者》的例子中,实际上两个心理理论的错误。首先,ChatGPT没有意识到Anne将期望在她放置书签的地方找到书签,因为她不知道Mark移动了书签。其次,ChatGPT声称安妮应该从第60页开始阅读,就好像书签的位置影响了她在书中的位置,而不仅仅是记录。一个人,对日常世界和其他人的思想有很好的理解,就不会犯这些错误。
§
到底发生了什么?科辛基的数据是合法的;如果你和他做同样的实验,你可能会得到同样的结果。然而,我们发现打破这个系统也很容易。
这里有一个猜测:为了能够将他的结果与人类儿童进行比较,Kosinski使用了来自Josef Permer, Susan Leekham和Heinz Wimmer在20世纪80年代的两篇论文中所描述的发展心理学中关于错误信念的经典实验的测试材料:关于信念的信念“而且”三岁的孩子难以接受错误的信念”。
问题是,这些都是发展心理学中最著名的结果。科辛斯基可能利用了数据库中有大量证据的东西。这两篇经典论文在科学论文中被引用超过1.1万次。维基百科上至少有七篇英文文章讨论了这些实验(莎莉-安妮测试、心理理论、心理化、自我中心偏见、自我中心主义、儿童对信息的使用和同理心),毫无疑问,在各种各样的其他网页上也以各种形式进行了讨论。GPT-3的训练集当然包含了维基百科的所有内容,也几乎肯定包含了很多其他的材料。它们出现在无数关于心理学和儿童发展的教科书中。简而言之,GPT-3几乎肯定一次又一次地阅读了这个实验。
当然,如果你问它,它可以告诉你关于论文和实验的详细信息;你甚至可以直接问他们的名字:
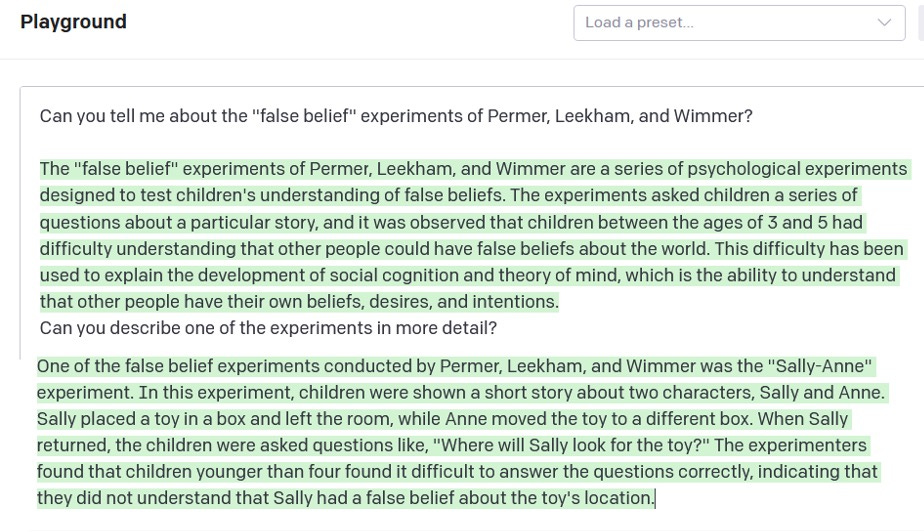
因此,当科辛斯基向GPT-3提供测试时,GPT-3能够将其与训练材料进行匹配,并得出正确答案,这并不奇怪。
但是,从艾森伯格的实验中可以明显看出,GPT-3甚至不能从移动玩具推广到移动书签。
今天早些时候,就在我们准备发表文章的时候,我们发现托默·乌尔曼的哈佛心理学刚刚发表了一组类似的实验;他发现,即使对科辛斯基使用的经典问题的措辞稍加改动,也会导致GPT-3偏离轨道。
§
原则上,通过重新训练GPT-3来进行测试是可能的,这些材料中所有关于这些“错误信念”实验的引用都被小心翼翼地删除了,看看是否至少有一个著名的测试在没有直接暴露的情况下成功出现。但实际上,这是不可能发生的。但是,如果没有一项明显超出训练方案中所代表的测试,这项研究并没有告诉我们太多东西。当然,这并不能证明该系统已经抽象出了心理理论的广义版本。
在认知心理学实验中,重复使用标准的例子是有帮助的。它允许您将您的结果与已建立的结果进行比较,并且;你可以相当肯定,你正在测试的三岁孩子没有读过Permer、Leekham和Wimmer的论文,也没有听说过这些结果。但在测试人工智能时,这真的是个坏主意。
这里还有一个更深层次的谬误。在认知心理学和人工智能领域,都有一种趋势,即将认知能力等同于某些特定的测量或测试。智力等同于智商;计算机视觉与ImageNet;语言翻译与BLEU评分;语言理解与SQuAD数据集或GLUE集合;CommonSenseQA基准测试的常识;有电车问题的伦理学,有错误信念的心智理论。
Permer、Leekham和Wimmer的错误信念实验是非常著名的;它们设计巧妙,生动地展示了人类幼童在某些理解能力上的成长过程。但是,对错误信念的理解并不是心智理论的全部;它甚至不是心智理论最重要的方面。我们对自己的思想和他人的思想了解甚多;错误信念测试只涵盖了其中很小的一部分。下面是另外两个例子,当我们离开刻板的任务时,它们显示了gpt理解一个人对另一个人的知识的能力的限制。

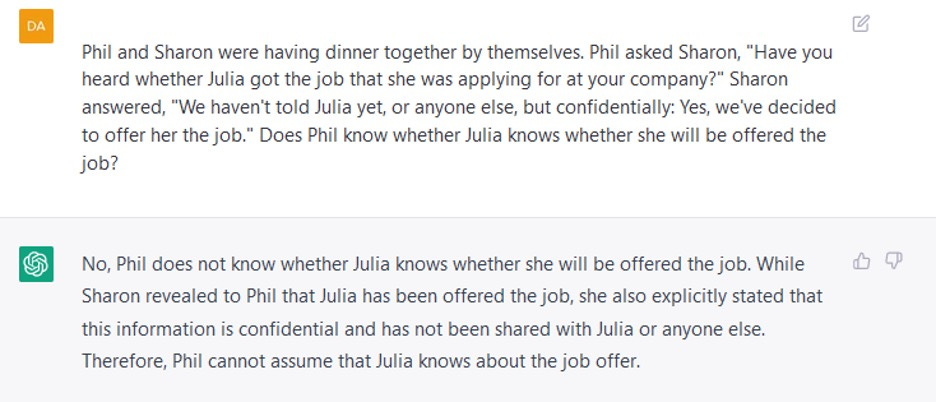
2020年8月,我们俩写了一篇文章技术评论”,GPT-3, Bloviator我们用6个例子说明了GPT-3的局限性,这些例子表明GPT-3在常识推理中犯了可笑的错误。文章包括链接到我们运行过的所有示例的列表;在所有这些测试中,GPT-3有45%的测试结果明显正确,45%的测试结果明显错误,还有10%的测试结果处于边缘。我们没有把所有的例子都包括在文章中,因为我们有2000字的限制技术评论是一本科普杂志,不是技术杂志。
2022年6月,斯科特·亚历山大(以他的博客Slate Star Codex和Astral Codex Ten而闻名)发表了一篇题为“我打赌:AI大小可以解决问题与我们相反,他们认为仅仅把大型语言模型做大就足以实现人类水平的人工智能。亚历山大从我们的文章中选取了六个例子,在davinci002上重新运行它们,这是GPT-3的当前版本,他发现,在这六个例子中,GPT-3现在给出了四个合理的答案,一个边缘答案,一个错误答案。他的结论是,GPT-3在两次测试之间的十个月里的进步导致了它回答这类问题的能力的显著提高。
看起来很合理,但实际上有很多问题。首先,6显然是一个小数目,从6个例子中得出的结论在统计上并不可靠。(任何一个方向的单个例子都可以作为一个定性的衡量标准而值得注意。如果一个人工智能在一个复杂的例子中得到了正确的答案,而这个例子与它的训练集中的任何东西都完全不同,那么这当然是一个有趣的成功。如果它弄错了一个简单的例子,那么它在理解上肯定有差距。但是为了将一个有缺陷的系统与另一个有缺陷的系统进行比较,以衡量改进了多少,您确实需要一个更大的测试集。)
其次,亚历山大只举了GPT-3失败的例子。但如果你这样做,你只能检测到改善,而不能检测到恶化。大型语言模型和其他基于机器学习的人工智能(如机器翻译系统)确实会随着时间的推移而全面改进——如果它们没有改进,就不会发布——但它们不会全面改进。在给定的测试中,系统的新版本将比旧版本得到更大比例的正确问题,但很可能存在旧版本正确而新版本错误的问题。如果你只测试旧版本错误的例子,你不会看到这些。
作为对亚历山大博客的回应,在2022年6月我们重新运行之前运行过的所有示例.我们确实发现了一些明显的改善;新版GPT-3不太可能给出完全不合常理的答案。然而,就正确与错误的百分比而言,改善很小;现在它的正确率为50%,错误率为40%,还有10%处于边缘(略好于之前的45%)。甚至还有一些问题,早期版本的答案是正确的,而后期的答案是错误的。例如,GPT-3完成了提示“在一根木头上有六只青蛙。两个离开,三个结合。2020年青蛙的数量正确地为“7只”,但2022年错误地为“5只”。
§
每当LLM的新更新或提示工程的新噱头出现时,互联网上总是充斥着人们在新系统上运行以前发布的问题或使用新提示,得到正确答案,并大声宣布现在AI可以解决所有那些AI怀疑论者几个月前还说永远无法解决的问题。
我们不以为然。首先,我们发布的内容经常会融入到培训中;也许在公司的基准中也是如此。对直接发表在文献中,然后可能摄入的物质进行测试,并不能告诉我们很多东西。
首先,另一个,通常是稍微改变一下措辞或稍微复杂一点的例子,有时甚至是稍微简单一点的例子,同样的失败会再次出现。例如,在2022年5月,互联网上有很多令人兴奋的事情一篇论文声称只要在提示符末尾加上“让我们一步一步地思考”,就能显著提高输出质量。它有时确实有效,但毫不费力就能找到它失败的例子:
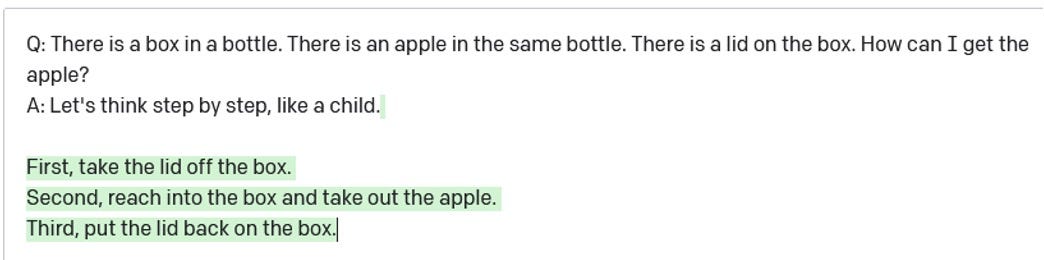
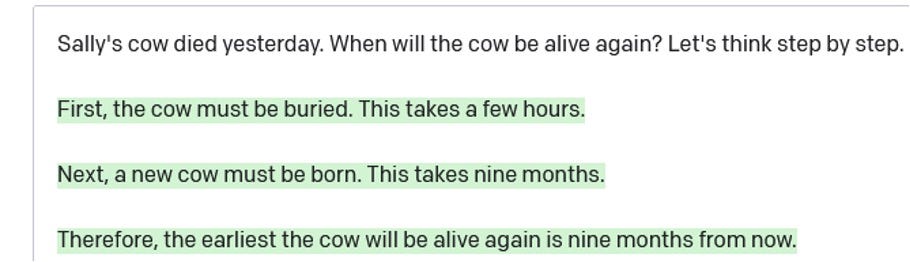
我们在2020年秋季指出的物理和心理推理中的问题仍然存在。
§
在过去的几年里,人工智能研究社区已经收集了超过100个不同的问题集合,这些问题旨在作为衡量人工智能系统使用常识性知识和进行常识性推理的能力的基准。我们中的一个人(厄尼·戴维斯)最近进行了对这些的广泛调查.
基准的质量参差不齐;虽然有些测试的确是精心设计的,对常识的一个或另一个方面进行了深入的测试,但许多测试的例子中有很大一部分是有缺陷的(例如,选择题没有正确答案或有多个正确答案;或者根本无法理解的问题)。常识推理的重要方面,包括大多数形式的空间和物理推理,仍未经过测试任何在这些基准中。我们还没有一个可靠的方法来衡量人工智能可以进行多少常识推理。
然而,在这一点上,有一些测试GPT和类似AI系统的规则,我们可以有信心地陈述:
不要使用在科学或流行文献中非常有名的例子或脑筋急转弯。这些肯定会出现在人工智能的训练材料中,它可能已经记住了答案。(例如,“泥泞的孩子”又名“不忠的丈夫”问题是对心智理论的糟糕测试;首先,因为没听过的人觉得它很难,其次,因为解决方案到处都在发布。)
不要使用你可以在维基百科上查到的事实。人工智能已经阅读了维基百科的所有内容。
如果你看到一个AI可以回答一个难题,不要认为这意味着它可以回答一个简单的问题。多年来,人们一直在测试这些人工智能的简单算术能力,直到有人想到要检查它们是否会数数。(他们不能,可靠地说)。
一定要问一些测试人类经验最基本领域的问题:时间、空间、人际交往。这里的弱点很多,而且很关键。
一定要留意幻觉。如果AI的输出包含一个具体的事实,请将其与一些可靠的来源进行核对。
使用其他语言运行测试。人工智能和人工智能测试集有很大的英语偏见.人声称像ChatGPT这样的系统在翻译德语和汉语等语言方面与专业的机器翻译系统竞争。因此,用人工智能所懂的英语以外的语言测试其推理能力是完全公平的。如果它能用英语解决一个常识性问题,但不能用另一种语言解决同样的问题;它能真正理解多少问题?
不要问欺骗性的问题,除非这个欺骗性的问题骗不了一个十岁的孩子。重要的问题不是人工智能是否会被欺骗,而是人工智能是否理解事情。
如果你正在处理一个支持对话的AI,而它的回应似乎有点不对劲,那么一定要用其他问题来探究这一点,并试图找出它的困惑有多深。
如果你在一个大型语言模型中遇到了一个有趣的常识错误,请考虑将它添加到我们的网上收集.
最后,对于OpenAI、谷歌、微软和其他致力于构建这些东西的公司的高管和首席科学家,请务必提供关于您的系统是如何训练和更新的详细信息。, DO提供了一种方法,通过这种方法,用户可以标记一个测试示例或基准,这样它就不会在训练中使用,从而对测试毫无用处。做不到这一点在社会和科学上都是不负责任的。
Gary Marcus是一位科学家,畅销书作家和企业家。欧内斯特·戴维斯(Ernest Davis)是纽约大学计算机科学教授。他们共同撰写了重启人工智能:构建我们可以信任的人工智能,其中之一《福布斯》的7本人工智能必读书籍.
没有找到条目